请到下载页先下载安装官方原版后,再下载补丁解压至安装路径覆盖原文件即可。
下载的论文都是pdf版本的转换出来的又是图片怎么办?这个工具可以直接提取pdf文档里的文字,你懂的。
ABBYY FineReader 是世界排名第一的 OCR 文字识别工具,提供高效和精准的文档识别、数据提取解决方案,支持多国字符和彩色文件识别,主要用于将扫描图像、图片型PDF转化成可编辑的文本。
ABBYY FineReader 可以看作是超级无敌的 PDF 转换器,能转换任意类型的 PDF,其他 PDF 转换工具、或清华紫光OCR、尚书七号、汉王OCR等在它面前都可谓是浮云。比较常用的功能为:扫描到 Word、将PDF/图像、图片转换为 Word 文档或者可编辑/可搜索的PDF文档,另外也支持将PDF/图像转换为 Excel 文档。
作为目前最好的OCR识别软件,FineReader 目前支持23种界面语言,多达189种OCR识别语言,包括其中几种语言的混合识别和结构复杂的文字识别;本次绿色版还保留了泰比 ABBYY Screenshot Reader 以及泰比 ABBYY Business Card Reader,分别用于将截屏图片转化成文字和名片扫描。
专业的OCR识别技术意味着软件体积的增大,如果需要轻量级OCR解决方案,可以使用 Able2Extract,就是只支持英文语言识别比较遗憾,不过 CAJViewer 提供了比较方便易用的中文OCR技术。
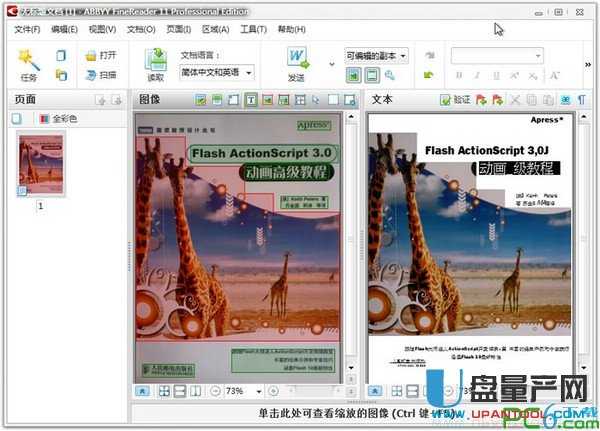
* OCR识别精度达到99%的先进OCR识别技术可以使您无需录入和排版就可以数字化您的文档;
* ADRT技术可以完美还原文档的逻辑结构和格式;
* 先进的数码相机OCR识别技术;
* 与PDF文件广泛协同;
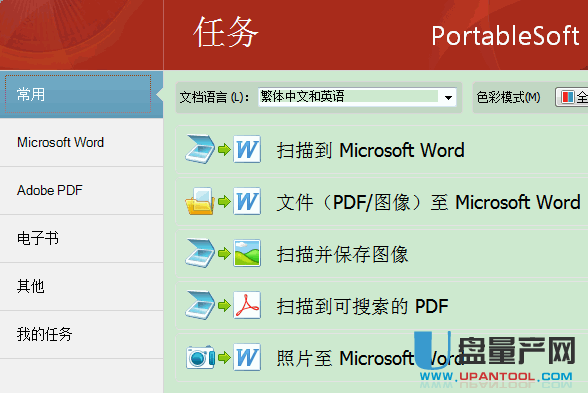
* 通过预先定义的快速OCR识别任务来处理文件。
本资源为网盘资源哦,大家只要输入提取码:wi62能提取到相应的资源啦!